February 28, 2026
·
17 min read
Advanced ways to rank your site on Google
An advanced pillar guide to ranking your site on Google—understand the modern ranking model, close intent gaps with entity-first topical coverage, build resilient architecture and crawl efficiency, and scale links, E-E-A-T, and refresh systems that hold up through updates.

If your rankings bounce after every update, it’s usually not “bad content”—it’s missing systems: the wrong intent match, thin entity coverage, crawl waste, or an architecture that splits relevance.
This pillar breaks down how Google evaluates pages today and what to do about it. You’ll learn how to find hidden intents in the SERP, design hubs that concentrate authority, control index bloat with log-file data, win (or avoid) SERP features, and build repeatable link, E-E-A-T, and refresh engines that compound.
Modern ranking model
Google’s ranking behaves like a stack of systems, not a single score. Think “relevance first, then quality, then usability, then trust,” with each layer adding constraints. A page can look perfect on-paper and still lose because it fails the job implied by “best running shoes” versus “running shoe size chart.”
System layers
Google processes your page in layers, and each layer has different levers. If you push the wrong lever, nothing moves.
Query understanding
- Interprets intent, entities, and modifiers
- Rewrites queries into “tasks”
Retrieval
- Selects candidates from the index
- Uses topic and term signals
Ranking
- Orders candidates by relevance and quality
- Weighs links, content, and context
Re-ranking
- Adjusts for freshness, locality, and personalization
- Applies spam and safety classifiers
Influence points
- Understanding: match language and intent cues
- Retrieval: build topical coverage and internal links
- Ranking: earn links and demonstrate expertise
- Re-ranking: maintain freshness and UX
If you’re not being retrieved, ranking tweaks are just noise.
Signal interactions
Ranking signals don’t add up linearly. They multiply, decay, or get zeroed out.
- Topical authority amplifies link value.
- Freshness decays faster in newsy SERPs.
- Intent mismatch nullifies strong authority.
- Poor UX suppresses otherwise great relevance.
- Trust gaps cap your ceiling.
When one signal gets zeroed, the rest can’t save you.
Optimization boundaries
Some constraints don’t yield to brute force, no matter how many pages you publish. You can’t manufacture intent, compress trust, or skip time.
Your real leverage points compound:
- Clarify the job-to-be-done per query class.
- Build clustered coverage that earns retrieval.
- Create reputation signals others control.
Stop trying to win every signal. Win the constraints that gate the whole system.
Intent gap analysis
Intent gap analysis finds the quiet mismatch between what your page promises and what the SERP rewards. You’re not hunting “missing keywords.” You’re hunting missing satisfaction, like ranking with a guide while users want a calculator.
SERP clustering
Cluster SERPs by intent and format before you touch content, because Google already did the sorting for you.
- Export the top 10 results for each query and capture SERP features.
- Tag each SERP by dominant format: article, tool, video, forum, local.
- Note recurring blocks: snippets, PAA depth, videos, local packs.
- Group queries when the top results and features overlap heavily.
- Name each cluster by intent, like “compare,” “buy,” or “fix.”
If the features match, the intent matches, even when the keywords don’t.
Hidden intents
Blended intent shows up when Google can’t fully commit, and neither can your competitors.
- Inconsistent titles across top results
- Mixed formats: guides, tools, product pages
- Volatile rankings week to week
- Long-tail modifiers shifting the layout
- PAA questions changing by location
When you see three or more signals, you’re looking at a split SERP you can design for.
Rewrite for intent
Rewrite by aligning your promise, your structure, and your entity coverage to the winning intent, not your original outline. Keep one URL, but add a clear secondary path, like “how it works” plus “best options,” without turning the page into a junk drawer. Add the entities the top pages mention, then earn differentiation with one unique job, like a template, checklist, or interactive step.
Entity-first topicality
Google increasingly ranks pages that model a topic like a mini knowledge base, not a bag of keywords. If your page reads like “tax deductions 2026” but never defines the entities involved, you look shallow.
Entity map
You need an entity map so your content reflects how the topic connects in the real world. It also gives you a clean blueprint for hubs and internal links.
- Pick one core entity and its canonical name.
- List attributes users expect, like price, specs, eligibility.
- Add related entities: alternatives, components, tools, regulations.
- Score edges by importance, using SERP overlap and user intent.
- Turn strong edges into hub pages and internal link targets.
Once you can draw the graph, you can stop guessing your site structure.
Coverage thresholds
You’re not aiming for “complete.” You’re aiming for “enough to rank,” based on what winning pages consistently cover.
Look for required subtopics, like definitions, comparisons, steps, and pitfalls. Then match the dominant page pattern, like tool, guide, or category page. Finally, find omissions that correlate with top results, like missing constraints or edge cases.
Your fastest wins usually live in the boring gaps competitors skipped.
Schema pitfalls
Schema should clarify your entities, not decorate thin content. Bad markup creates contradictions Google can ignore.
- Mark up entities your page does not cover.
- Use inconsistent IDs across pages for the same entity.
- Publish FAQ schema with thin, repetitive answers.
- Over-mark every block, including obvious text.
- Add schema that conflicts with on-page claims.
Schema helps when it matches reality, and hurts when it signals confusion.
Information architecture
Information architecture is how you bottle relevance and pour it where rankings need it. Done right, it feels like a clean library, not a cluttered warehouse. Think “one hub, many spokes” instead of 40 near-duplicate posts fighting each other.
Hub design
Hubs work because they create a clear center of gravity for a topic. Your job is choosing a shape that matches how people search and how you sell.
Broad topic hub pattern:
- One authoritative hub page targets the head term.
- Spokes cover distinct subtopics and questions.
- Supporting pages handle edge cases and updates.
- Each spoke links back with a consistent, descriptive anchor.
Narrow commercial cluster pattern:
- One money page targets the core transactional query.
- Comparison pages cover “X vs Y” and alternatives.
- Use-case pages map to industries and jobs-to-be-done.
- Proof pages include case studies and reviews.
If your hub can’t explain the topic in five links, you don’t have a hub. For a broader framework, see this step-by-step SEO guide.
Link weighting
Not all internal links carry the same practical weight in Google. You control emphasis with placement, repetition, and anchors.
- Prioritize contextual links inside the main content block
- Limit template links to true navigational essentials
- Use link blocks for “next best click” pages only
- Refresh anchors to match intent, not keyword lists
- Add links gradually to avoid sudden graph noise
If everything links to everything, nothing looks important.
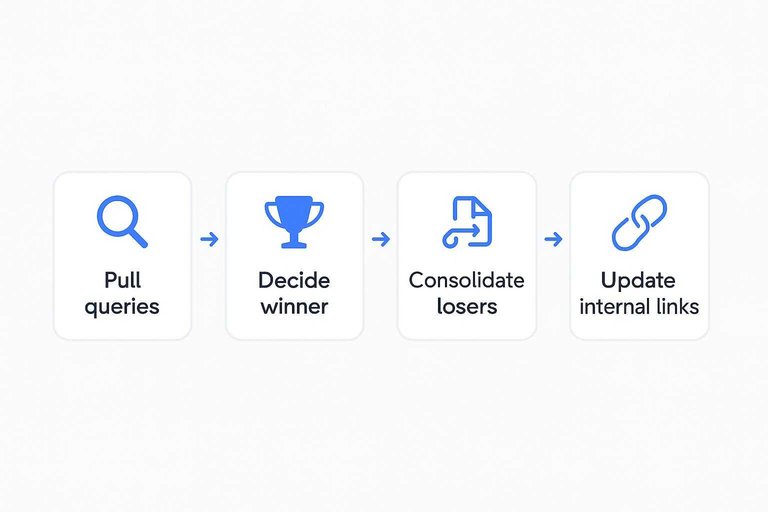
Cannibal control
Cannibalization happens when two pages promise the same outcome to Google. Fix it by enforcing one page per intent and routing signals cleanly.
- Pull queries where two URLs trade positions for the same intent.
- Decide the winner using conversions, links, and content depth.
- Split intent if needed: “definition” versus “best tools” versus “pricing.”
- Consolidate losers into the winner, then 301 redirect old URLs.
- Update internal links to point only at the winner URL.
You’re not deleting content. You’re deleting ambiguity.
Crawl budget leverage
On large or dynamic sites, Google spends crawl like a fixed budget. Your job is to steer it toward money pages, not “?color=blue&size=m” clones. Think “crawl what matters, index what holds steady.”
Index bloat triage
Low-value URLs multiply fast, and they dilute your strongest signals. You need a fast sorting system, not debates.
- Faceted navigation URLs with endless combinations
- Parameterized URLs that reorder the same listings
- Thin archives with one or zero items
- Internal search result pages and filtered searches
- Near-duplicate pages differing only by template blocks
Pick one action per class: noindex for utility pages, canonical for duplicates, pruning for dead weight. That choice sets your crawl boundaries.
Log-file decisions
Your logs show what Googlebot actually does, not what you hope it does. Use them to find waste, then tie each pattern to a fix.
- Export bot hits by URL pattern, status code, and depth.
- Flag bot traps like infinite facets and calendar loops.
- Find valuable pages with low hits or slow recrawls.
- Match each issue to a control: robots, noindex, canonicals, or internal links.
- Predict impact: fewer 404s, fewer duplicates, faster refresh on priority pages.
When crawl behavior changes in logs, rankings usually follow a few weeks later.
Rendering edge cases
JS-heavy sites can “look fine” to users while bots see blanks or partial content. That gap creates index lag, thin-page signals, and missed internal links.
Treat these as red flags: hydration delays that hide main content, infinite scroll that never exposes URLs, and content injected only after interaction. Your fix is parity: server-render critical HTML, expose paginated URLs, and keep titles, canonicals, and links present on first load.
If Google can’t see your page fast, it won’t trust it often.
SERP feature strategy
You can win page-one visibility without winning the top blue link. But some features steal clicks, so you need control, not just eligibility.
Treat SERP features like placements with rules, not “nice-to-have” decorations.
Feature eligibility
Different features favor different page shapes, and Google disqualifies pages fast. Map the feature to the page type before you write.
| Feature | Best page type | Prerequisites | Common disqualifiers |
|---|---|---|---|
| Featured snippet | How-to / definition | Clear H2 structure | Thin, salesy copy |
| FAQ rich results | Support / FAQ page | FAQ schema, Q/A | Misleading schema |
| Video result | Tutorial page | Embedded video, VideoObject | No indexable video |
| Image pack | Visual guide | Unique images, alt text | Stock-only images |
| Reviews rich results | Product / service page | AggregateRating schema | Self-serving reviews |
If you can’t meet prerequisites cleanly, don’t chase the feature on that URL.
Snippet engineering
Snippets follow repeatable formatting cues, not “better writing” vibes. Shape your page so Google can lift a clean answer.
- Lead with the entity, then the verb: “A canonical tag tells Google…”.
- Add a 40–60 word definition block under the first matching H2.
- Use list grammar for lists: same tense, same structure, no fluff.
- Prefer tables for comparisons: 3–5 rows, consistent units, simple labels.
- Keep headings literal: “Steps to…”, “Cost of…”, “Best… for…”.
If your formatting is predictable, Google’s extraction gets boring, and boring wins.
Zero-click risk
Some features answer the query so well that the click disappears. That’s common with simple definitions, weather-style facts, and “what is X” queries.
Protect demand with intentional incompleteness. Give the answer, then gate the value: “The range is 3–7 days, but the timeline depends on X, Y, Z.”
Your job is to make the next step feel necessary, not optional.
Link acquisition systems
Advanced link building is a system problem, not a hustle problem. You want links that look earned because they are earned, like a niche newsletter citing your benchmark in a “resources” roundup. Optimize for relevance, discovery, and trust, and updates stop feeling like roulette.
Prospecting filters
You need a short list you can defend, not a giant sheet you can’t prioritize. Filter for fit first, then worry about scale.
- Cover your topic cluster, not adjacent trivia
- Share your audience, not just your keywords
- Show real traffic, not bot spikes
- Publish with standards, not paid slots
- Link out naturally, not to “partners” only
If your pitch needs DA to sound convincing, your target list is already off.
Linkable assets
Links follow incentives, not effort. A “big guide” rarely beats a publisher-friendly asset they can reference in one sentence.
Build assets that create a clean citation:
- Original datasets with a simple download
- Lightweight tools or calculators with embed code
- Benchmarks that define “normal” in your niche
- Contrarian studies that challenge common advice
Match the asset to the publisher’s job-to-do, and outreach becomes routing, not persuasion.
Digital PR loops
You want a repeatable PR loop that produces fresh angles without spinning junk. Sequence matters because editors reward clarity and punish clutter.
- Write one sharp angle with a single proof point.
- Segment outreach by beat, then tailor the first line.
- Follow up twice with new context, not “bumping this.”
- When coverage lands, syndicate to secondary targets with the citation.
- Log objections and update your angle bank weekly.
Handle syndication like a trail of citations, not a copy-paste parade.
Stay inside the lines of Google’s link spam policy as you scale this loop.
E-E-A-T proof points
Google can’t “feel” trust, so it looks for evidence. Your job is to leave proof trails on the page and across your brand, like a visible review process or a named expert.
Treat E-E-A-T like operations, not vibes. The sites that win keep shipping small credibility upgrades that compound.
Author credibility
Anonymous content is a ranking liability, especially on competitive queries. Make the author legible, qualified, and accountable on every article.
- Write a specific bio, not “SEO writer”
- Link to credentials, affiliations, and profiles
- Cite primary sources and quoted experts
- Add “reviewed by” with role and date
- Publish update logs and change notes
When your author footprint is consistent, quality raters and algorithms see less risk.
Trust architecture
Trust pages aren’t legal filler. They’re internal links that explain who you are and how you handle mistakes.
- Add a real contact page with address or service area.
- Publish editorial guidelines with sourcing rules.
- Create a corrections page with a simple request flow.
- Make privacy, ads, and affiliate disclosures explicit.
- Clarify ownership: company, leadership, and funding.
Bake these into templates, or they’ll rot and disappear during redesigns.
YMYL hardening
YMYL topics need stronger brakes. If you publish health, finance, or legal advice, assume you’ll be judged on harm prevention.
Use a source hierarchy that favors guidelines, regulators, and peer-reviewed research. Add clear medical or legal disclaimers that say what you do and don’t provide, like “for education, not diagnosis.” Tie fact-checking to updates with named reviewers, timestamps, and archived prior claims.
If you can’t show your safety process, you’re asking Google to take a risk.
Performance beyond CWV
Your best speed wins often come from interaction quality, rendering stability, and clean measurement. If your data lies, you’ll “improve” the wrong thing and still lose rankings.
Measurement pitfalls
Lab scores are a wind tunnel, not the highway, so treat them as directional. Field data is the highway, but it’s noisy and easy to misread.
Lab vs field confusion: Lighthouse up, CrUX flat, because real devices differ. Sampling bias: only logged-in users measured, or only fast regions counted. Tag inflation: too many pixels slow pages and distort timings. Single-metric obsession: chasing LCP while INP and layout shifts wreck reads.
Validate with two sources, one cohort, and one change at a time. Otherwise you’re optimizing a dashboard, not a site.
High-impact fixes
Fixes that touch the critical path beat micro-optimizations, even when they’re annoying. Expect tradeoffs like more build complexity or less third-party flexibility.
- Inline critical CSS, defer the rest
- Preload key fonts, limit variants
- Serve AVIF/WebP, correct sizes
- Gate third-party scripts by consent
- Reduce hydration, ship less JS
If you can’t name the tradeoff, you probably didn’t change anything meaningful.

Mobile-first quirks
Mobile UX bugs quietly crush engagement signals, even when CWV looks “green.” They also trigger pogo-sticking, which your content can’t outwrite.
- Remove or delay interstitials until after first interaction.
- Audit sticky headers for content coverage and scroll-jank.
- Test viewport units on iOS and fix 100vh layout jumps.
- Enlarge tap targets and spacing for thumbs, not mice.
- Recheck forms and menus on slow 3G CPU throttling.
Mobile issues rarely show in desktop QA. They show in your rankings.
Content refresh engine
Rankings decay even when your content stays “accurate.” Queries get fresher, competitors iterate, and Google re-tests winners. Build refresh cycles that match the SERP’s tempo, not your publishing calendar—especially if you’re aiming for daily SEO gains with AI.
Refresh triggers
You need a small set of signals that force a refresh decision. Treat them like alerts, then score them for priority.
- Rank drift on core queries
- SERP churn in top results
- New entities in Knowledge Graph
- Broken citations or dead sources
- Outdated recommendations or tools
Prioritize by traffic value times drop speed, not by gut feel.
Update playbooks
Pick one playbook per refresh so changes stay coherent. Mixing styles creates messy pages and muddled intent.
- Additive expansion: add missing subtopics, examples, and FAQs without changing structure.
- Structural rewrite: rebuild sections to match current SERP intent and headings.
- Consolidation: merge overlapping pages and delete thin duplicates.
- Keep the URL when intent stays the same; change it only when intent changes.
- If you change it, 301 redirect and update internal links immediately.
URLs are promises; break them only when the page stops being the same page.
Change risk control
Refreshes fail when you “improve” the page into a different page. Control risk by protecting intent, link equity, and the update blast radius.
Keep the primary intent unchanged, even if you rewrite everything else. Preserve internal anchor targets, redirect cleanly when needed, and watch the 7–21 day volatility window after launch.
International and local
Ranking across borders is mostly about precision, not volume. One wrong signal can turn “en-gb” into “en-us,” or make ten city pages look like a doorway set.
Hreflang traps
Hreflang usually fails in boring ways, and boring failures scale fast. One broken return tag can quietly strand an entire language set.
- Missing return tags between alternates
- Canonical points to a different locale
- Parameterized URLs in hreflang clusters
- Locale codes don’t match content
- Sitemap and HTML tags disagree
Test at scale by crawling alternates, validating reciprocity, and diffing canonicals per cluster. If you can’t audit it weekly, you don’t control it.
Use Google’s official guidance on localized versions of your pages to validate implementation details.
Local intent blending
“Near me” queries reward proximity signals, but they punish copy-pasted city pages. Your job is to blend service coverage with real-world proof, like “24-hour plumber” plus reviews tied to the area.
Build one strong service page per offering, then add location context with service-area modules, embedded GBP details, and locally sourced reviews. That’s the line between relevance and thin location spam.
Multi-region IA
Pick a structure early, because migrations create years of SEO debt. Your IA should make one region the default, and everything else explicitly regional.
- Choose ccTLD, subfolder, or subdomain based on legal and ops needs.
- Map each region to a unique URL set with consistent templates.
- Wire internal links to prefer same-region navigation by default.
- Apply canonicals within region, and hreflang across regions.
- Monitor cannibalization with region filters in GSC and rank tracking.
Cross-region cannibalization is rarely a content problem. It’s an architecture problem you can fix.
Penalty and spam resilience
You can’t control every update or competitor, but you can control how fragile your site is. Design for resilience so a single bad signal doesn’t tank everything like a “sitewide link” mistake.
Build defense in layers, not luck.
A resilience plan looks like this.
| Risk | What triggers it | Early warning | Built-in defense |
|---|---|---|---|
| Manual action | Paid links pattern | Unnatural links notice | Link policy, audits |
| Algorithmic demotion | Thin, repetitive pages | Traffic drop by template | Prune, consolidate, improve |
| Link spam attack | Spammy new referring domains | Spike in low-quality links | Monitor, ignore, disavow sparingly |
| Reputation abuse | Fake reviews, brand spam | SERP “scam” modifiers | Review ops, brand pages |
| Index bloat | Facets, parameters, duplicates | Crawled not indexed | Canonicals, noindex, rules |
If your defenses are structural, Google updates become noise, not emergencies.
Turn the tactics into a repeatable ranking system
- Pick one high-value topic cluster and run an intent gap analysis against the live SERP, then rewrite pages to match the dominant and secondary intents.
- Build an entity map for the cluster, set a coverage threshold, and fix schema/IA issues that dilute topical signals (hub design, internal link weighting, cannibal control).
- Improve crawl and index efficiency using log files: prune bloat, resolve rendering edge cases, and prioritize URLs that support conversions and rankings.
- Layer on scalable growth loops—SERP feature eligibility + snippet engineering, linkable assets + digital PR, E-E-A-T proof points, and a controlled content refresh engine—so gains persist through updates.
Frequently Asked Questions
- Does social media help you rank your site on Google in 2026?
- Not directly as a ranking factor, but it often boosts discovery, branded searches, and natural link earning. Use it to seed content distribution and brand signals, then measure impact via Search Console and referral/link growth.
- How do I track if my changes actually help rank my site on Google?
- Use Google Search Console to compare clicks, impressions, average position, and query/page pairs over 28-day windows, and annotate release dates. Validate with server log data (crawl rate/index hits) and controlled on-page tests where possible.
- How long does it take to rank your site on Google after publishing or updating a page?
- Most sites see early movement in 1–4 weeks (indexing, re-ranking tests) and more reliable gains in 8–16 weeks. Competitive queries and sites with low authority often take 3–6+ months to reach stable top positions.
- Can you rank your site on Google without backlinks?
- Yes for long-tail or low-competition queries, especially with strong on-page relevance and a clean technical setup. For competitive SERPs, you usually need some level of authoritative links or equivalent off-site trust signals to break into top results.
- Should I use AI-generated content if I want to rank my site on Google?
- Yes if it’s edited by experts and adds unique value—Google rewards helpful content, not how it’s produced. Publish with clear human accountability (bylines, sources, original data/examples) and QA for factual accuracy to avoid quality downgrades.
Turn SEO Strategy Into Output
These advanced ranking tactics only work when you execute them consistently—publishing, refreshing, and building authority without letting technical details slip.
Skribra helps you rank your site on Google with daily SEO-optimized articles, WordPress publishing, and a backlink exchange network—plus a 3-Day Free Trial to validate results fast.
Written by
Skribra
This article was crafted with AI-powered content generation. Skribra creates SEO-optimized articles that rank.
Share: